
All day Monday, 12 August
All day Friday, 23 August
The office will be closed at the following period due to the University's summer holidays.
Saturday, 10 August - Sunday, 18 August
■What is NINJAL-LWP for TWC?
NINJAL-LWP for TWC (NLT) is a tool for searching the Tsukuba Web Corpus (TWC), a corpus of approximately 1.1 billion words collected from Japanese-language websites. The search function is based on the use of NINJAL-LWP (NINJAL-LagoWordProfiler), a corpus search system developed jointly by the National Institute for Japanese Language and Linguistics (NINJAL) and Lago Institute of Language. Among tools that utilize the same system is NINJAL-LWP for the BCCWJ (NLB), a tool for searching the 100-million-word Balanced Corpus of Contemporary Written Japanese (BCCWJ), which was developed by NINJAL.
This tool uses a method known as lexical profiling to comprehensively indicate the co-occurrence relations and grammatical behavior of nouns, verbs, and other content words.
■How to Use
With a concordancer, the results obtained by inputting a search string are returned as concordance lines. With NLT, you first select the word you wish to look up (referred to with NLT as a “headword”) rather than input a search string. There are five types of content words that can be looked up as node words: nouns, verbs, adjectives, adnominal adjectives and adverbs.

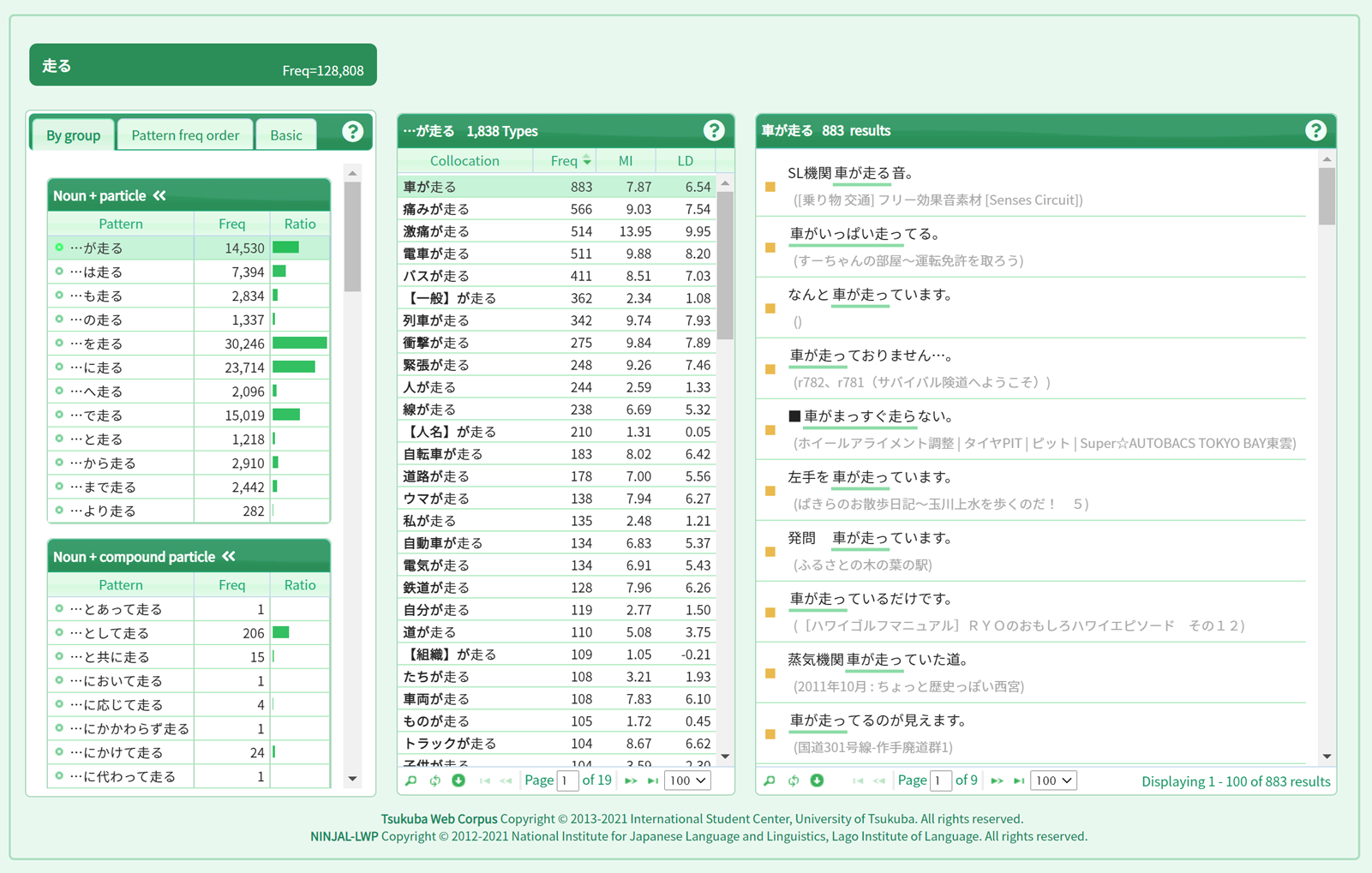
To illustrate, let us look up the verb “run”. First, enter “走る”, “はしる” (or with katakana characters), or “hashiru” in the input field on the screen and click the “Refine” button. Three node words that can be read as “はしる” appear in the list below; click on the “走る” that appears at the top of this list.

Click to open a node word window for “走る”. At this stage, you can try to figure out what nouns might appear before “が走る”. If you select “By group” in the left-hand panel of grammatical patterns, the “noun + postpositional particle <” group will appear at the top. Click on the “…が走る” pattern at the top.
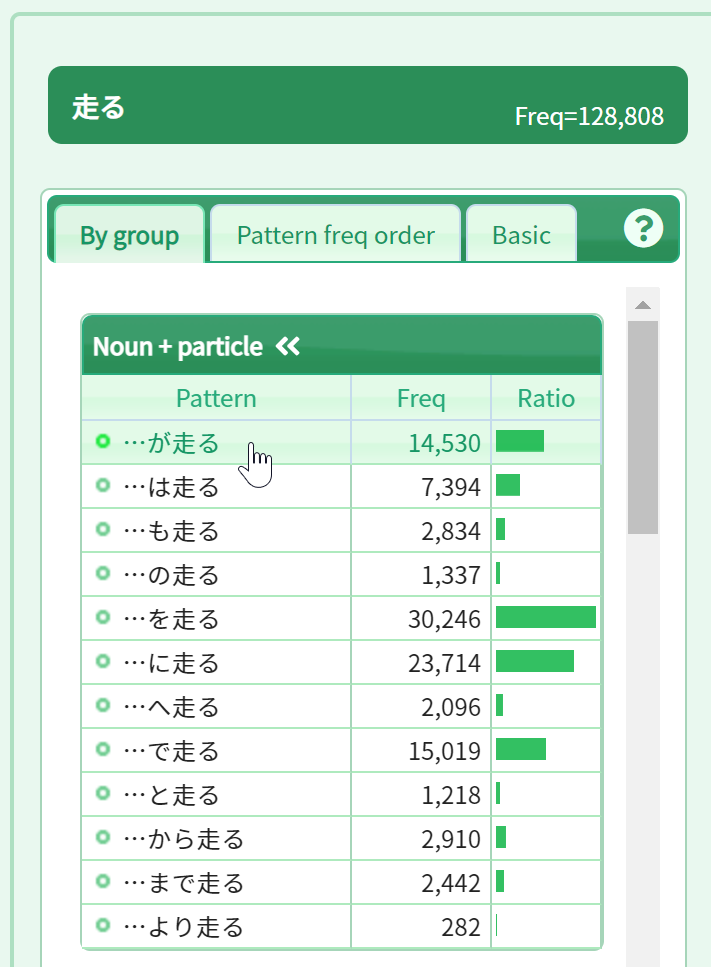
Collocations of “noun + が走る” will then appear in order of frequency in the collocation panel in the center of the screen. In the left-hand example panel, the most frequent example, “車が走る” (“a car is driven”), is shown.
Next, let us bring up characteristic collocations. With NLT, you can sort a list not just by frequency but also by MI score. The MI score is a statistical indicator that tends to be higher for more characteristic collocations. However, low-frequency collocations need to be excluded since they would otherwise be over-represented. Click on “MI” in the header of the collocation panel and then right-click on the top of the panel and select “Frequency of 20 or more”.
img src="/static/images/toppage/mi_score_en.png"/ style="margin-left:-5px;width:280px">You will then see such characteristic expressions of “noun + が走る” as “虫ずが走る” (“to be disgusted”) and “戦慄が走る” (“a shudder running through”) appear at the top.
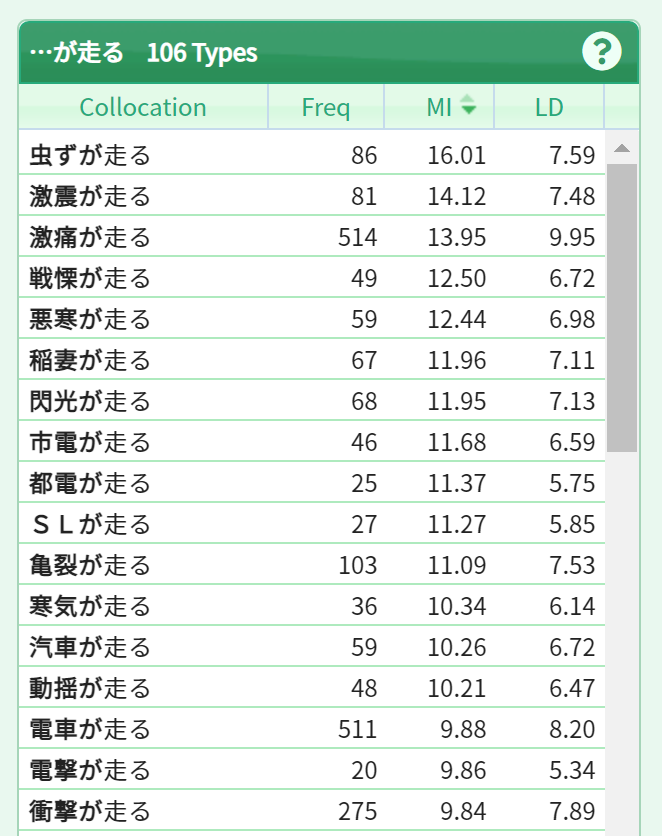
Click on each collocation to bring up corresponding examples in the right-hand panel. In this case, click on the seventh collocation: “閃光が走る” (“light flashes”). You can then individually check out actual examples as used in the corpus.
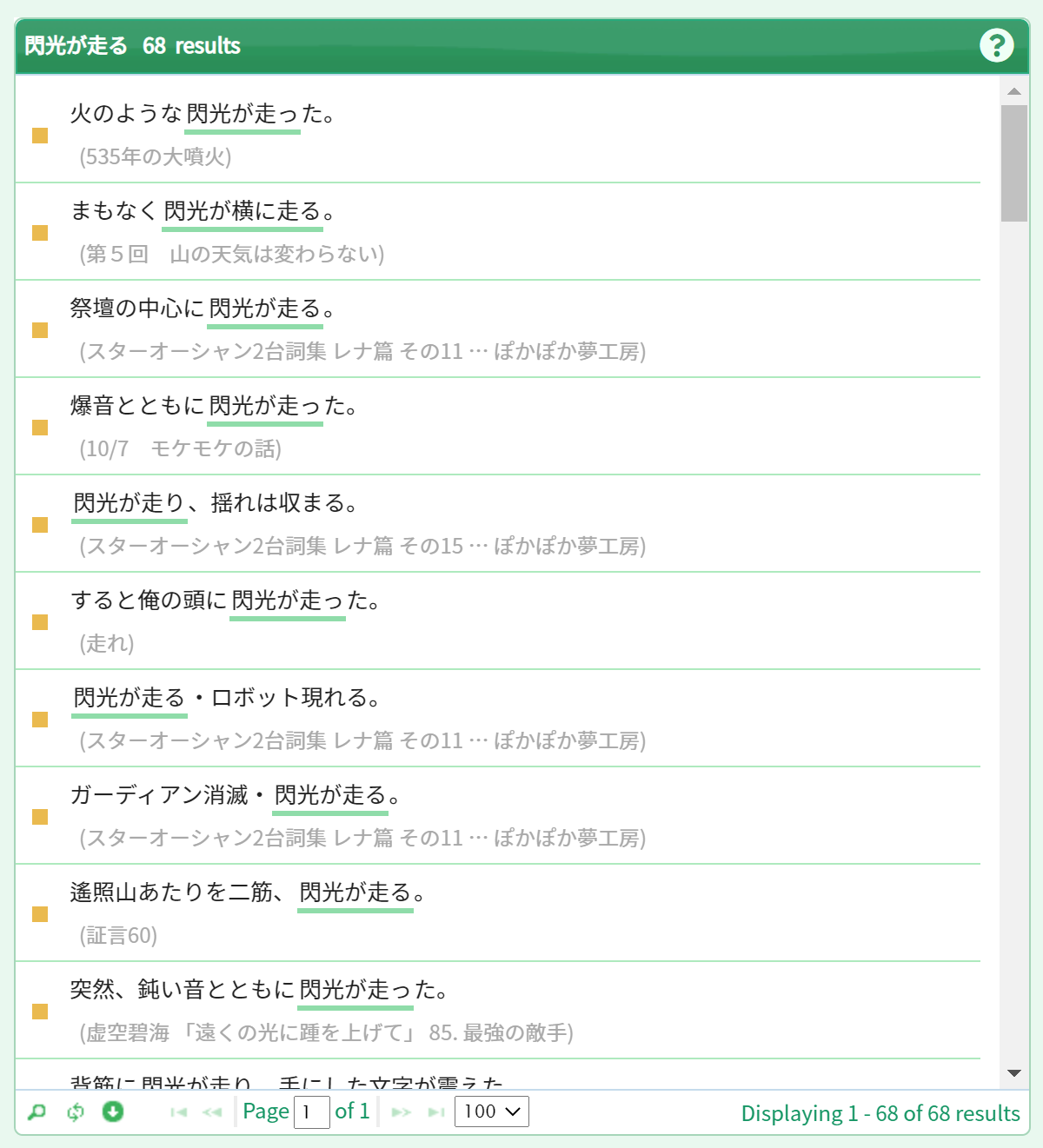
Examples are shown in sentences. If you wish to check out the context for an example sentence, click on the source for the example sentence in question to open up a dialog window that displays the sentences that appear before and after the example sentence.

In this way, NLT allows you to first select a node word in the search window and then, in the node word window, go back and forth between grammatical patterns, collocations, and examples to obtain a complete picture of the way the node word behaves. Since this tool can be easily operated just by engaging in clicking actions, you can look up a wide range of expressions tied to a node word at will without losing your train of thought.
See the user guide (PDF file, approx. 2.8 MB, Japanese) for more detailed instructions.
■Building the Tsukuba Web Corpus
TWC ver. 1.40 utilizes data consisting of 1,138 million words collected from Japanese-language websites.
In collecting text from the Internet, we went with a typical method by which we used a search engine API to collect web page URLs and then collected data from these URLs. The following are the specific steps we used to build our corpus.
| ● | Generating seeds and tuples | |||
| For seeds that make up the tuples that are given to a search engine query parameter, we used frequency lists corresponding to the BCCWJ (part of the domain public data for 2009; approximately 62 million words), which was produced in the course of developing NLB. Among the frequency lists divided according to parts of speech, we merged lists of content words consisting of nouns, verbs, adjectives, and adverbs and selected the top 500 words as seeds. However, nouns consisting of numbers and proper nouns were excluded while the conjugated forms of verbs and adjectives were included. We randomly selected three words from among these 500 seed words and then produced a total of 500,000 sets of tuples. Tuple examples are shown below. | ||||
| ||||
| ● | Collecting URLs using a search engine API | |||
| The Yahoo! Web Search API was used to collect URLs. From the beginning of January 2012 to the end of the same month, a total of 5 million URLs were collected at a rate of 10 URL pages collected per tuple. After removing duplicate URLs, the total number of collected URLs was reduced by approximately 30% to 3.5 million. | ||||
| ● | Collecting HTML pages | |||
| Upon splitting up the URL data into bundles of 50,000 URLs each, three terminals were used to collect HTML pages over a two-week period. | ||||
| ● | Extracting text | |||
| Next, work to extract text from collected HTML files was undertaken. Specifically, HTML tags were removed, character encoding was unified (utf8), text written in languages other than Japanese was deleted, and other actions were performed. | ||||
| ● | Eliminating inappropriate pages | |||
| Since the purpose of collecting text on the web is to extract examples of the use of Japanese, pages that simply list items or links, pages that have a substantial amount of content that can be considered advertising, and pages for which boundaries between sentences may be difficult to determine were excluded from the scope of corpus data in advance. | ||||
| ● | Extracting sentences | |||
| With lexical profiling tool NINJAL-LWP, extraction by grammatical pattern was performed to determine the types of collocation included in sentence-unit examples. For this reason, the corpus data needed to be split up into sentence units in advance. This also explains why pages for which boundaries between sentences may be difficult to determine were eliminated in the preceding step. | ||||
| ● | Extracting example data | |||
| Sentence-unit data included data corresponding to headings and data corresponding to menu items. We extracted data that we deemed to be appropriate as examples as determined by quantifying the appropriateness of each sentence for use as an example from multiple standpoints, such as in terms of the extent to which nouns are included in the sentence, whether there is a verb in the sentence, and whether expressions commonly used on web pages, such as click and login, appear in the sentence.. We also took measures to avoid unnecessary duplication in the event of the same sentence appearing on the same page by extracting only the first sentence for use as an example. | ||||
| ● | Removing duplicate example data | |||
| We made arrangements in the preceding step to prevent the same example from being extracted multiple times from the same page but, upon developing and actually running the pilot version of NLT, with just under 600 million words, we found that the same example from the same site would appear frequently. For this reason, we made improvements to ensure that the same example from the same site would be extracted just once based on information corresponding to the URL and finally completed the Tsukuba Web Corpus with 1,137.81 million words and 46.727 million examples. |
■Annotations
In order to extract information on collocation and grammatical behavior with NLT, we applied annotations to the BCCWJ data and analyzed this data. The analyzers and dictionaries used for these annotations are set forth below.
■Terms of Use
| 1. | Operating environment: The following browsers are supported: Firefox, Chrome, Safari, and Internet Explorer (version 8 or higher). We recommend that you use Firefox, Chrome, or Safari from the standpoint of processing speed. | |
| 2. | Cookie setting: When using this tool, please enable browser cookies. If cookies are disabled, data will not be displayed. See the instructions for the browser of your choice for more information on how to turn on cookies. | |
| 3. | Display results: With NLT, machine-processed results are displayed without modification. Be aware that inappropriate results may be included in the results due to limitations in terms of the accuracy of the morphological and dependency analysis and extraction processing. | |
| 4. | When publishing a paper or article: If you use NLT for research and education purposes in writing a paper or article, make sure to indicate the fact that you used NLT and contact the Center for Distance Learning of Japanese and Japanese Issues of the University of Tsukuba International Student Center (jp-kyoten(insert an at-mark here)un.tsukuba.ac.jp).
| |
| 5. | Request to remove an example: This corpus constitutes a collection of data from the web for the purposes of education and research. All examples are presented with citations of source page titles and URLs. If you wish to have an example extracted from a web page to which you own the copyright removed, please contact us via email address used for inquiries. An example will be removed once we verify that the page in question belongs to you (as the applicant). |
■Headword Frequency List
This is a list of headword frequencies as compiled in an Excel file format (.xlsx). The use of this list is limited to research and educational purposes. For more information, read the “Terms of Use” section in the file.
■History of Updates
| April 15, 2013 | NLT ver. 1.10 released. |
| March 27, 2015 | NLT ver. 1.30 released (added function to enable two-word comparison searches). |
| April 26, 2019 | Headword Frequency List released. |
| November 16, 2020 | Domain name changed to tsukubawebcorpus.jp; always SSL enabled. |
| March 7, 2021 | NLT ver.1.40 released (multiple-language version). |
| September, 28, 2023 | Corrected "adjective-verb" patterns of verb headwords. |
■Inquiries
Inquiries concerning NLT should be submitted to the following:
jp-kyoten(insert an at mark here)un.tsukuba.ac.jp