
メンテナンス点検のため、以下の期間、サービスを一時休止いたします。
8月12日(月)終日
8月23日(金)終日
大学の夏季休業に伴い、下記の期間で事務室が閉室となります。
8月10日(土)~8月18日(日)
■NINJAL-LWP for TWC とは
NINJAL-LWP for TWC(ニンジャル・エルダブリュピー・フォー・ティーダブリュシー、略称NLT)は、日本語のウェブサイトから収集して構築した約11億語のコーパス『筑波ウェブコーパス』(Tsukuba Web Corpus: TWC)を検索するためのツールです。検索には、国立国語研究所(以下、国語研)とLago言語研究所が共同開発したコーパス検索システムNINJAL-LWP(NINJAL-LagoWordProfiler)を利用しています。同じシステムを利用したツールに、国語研が構築した1億語の『現代日本語書き言葉均衡コーパス』(Balanced Corpus of Contenporary Written Japanese: BCCWJ)を検索するNINJAL-LWP for BCCWJ(NLB)があります。
このツールはレキシカルプロファイリングという手法を用いて、名詞や動詞などの内容語の共起関係や文法的振る舞いを網羅的に表示することができます。

■使い方
コンコーダンサでは検索語句を入力すると、その結果がコンコーダンスラインとして返ってきます。NLTでは、検索語句を入力する代わりに、まず調べたい語(NLTではこれを「見出し語」と呼びます)を選びます。見出し語として選べるのは、名詞、動詞、形容詞、連体詞、副詞の5種類の内容語です。
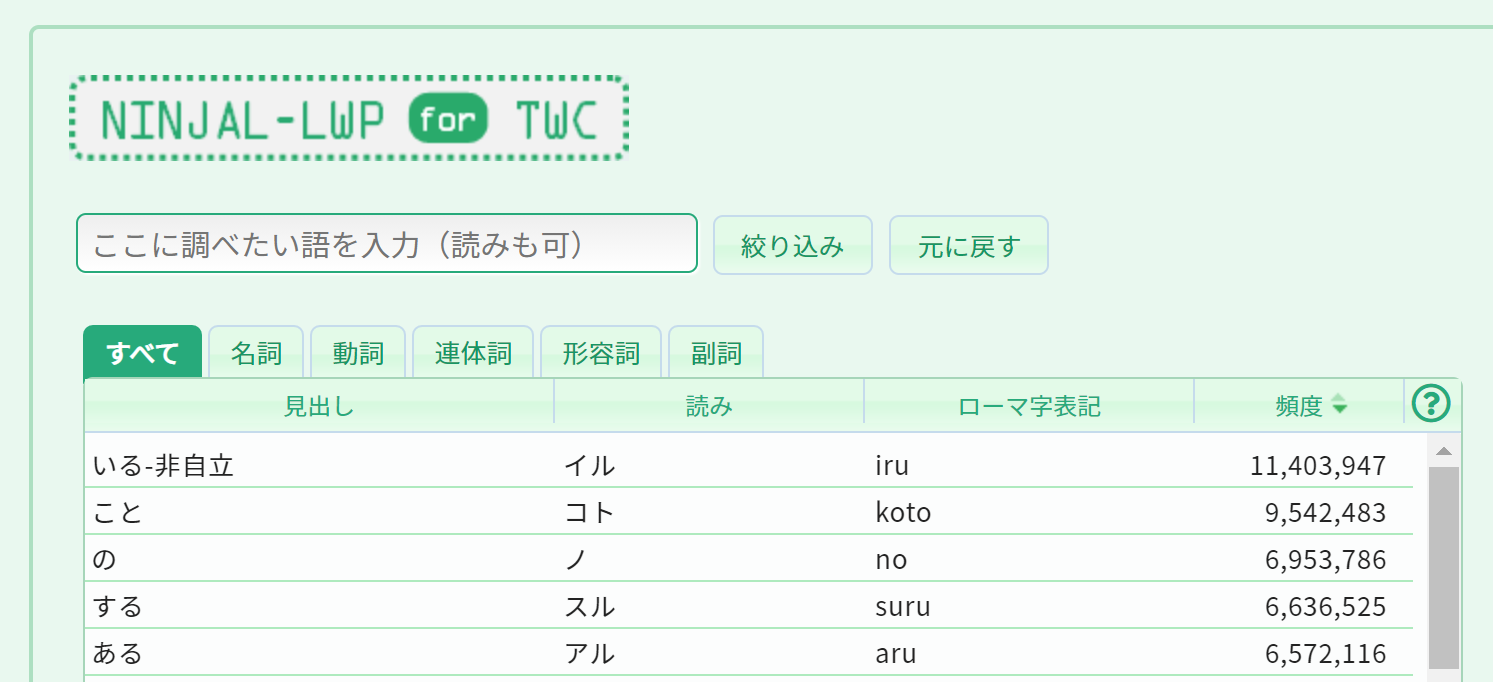
ここでは、「走る」という動詞について調べてみます。まず画面上の入力ボックスに「走る」または「はしる」(カタカナも可)または「hashiru」を入力して、[絞り込み]ボタンをクリックします。下のリストに「はしる」という読みの見出し語が3つ表示されますので、一番上の「走る」をクリックします。

クリックすると、「走る」の見出し語ウィンドウが開きます。ここでは、「が走る」の前にどのような名詞が来るかを調べてみることにします。左側の文法パターンのパネルの[グループ別]を選ぶと、一番上に[名詞+助詞 <]グループがあります。一番上の[…が走る]というパターンをクリックします。
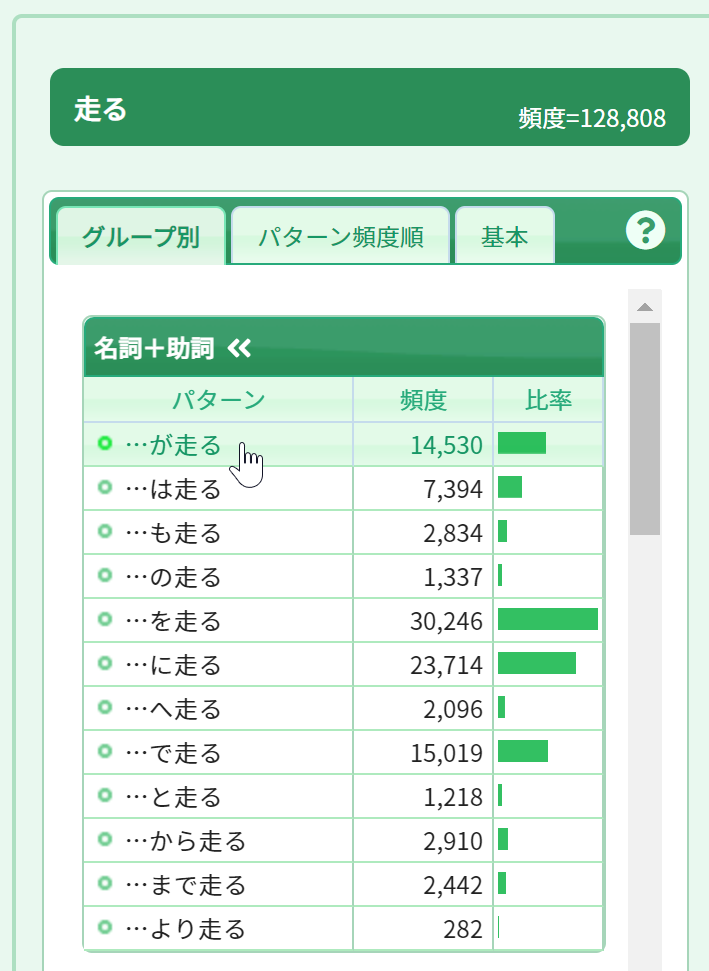
すると、中央のコロケーションパネルに[名詞+が走る]のコロケーションが頻度順に表示されます。左側の用例パネルには、最も頻度の高い「車が走る」の用例が表示されます。
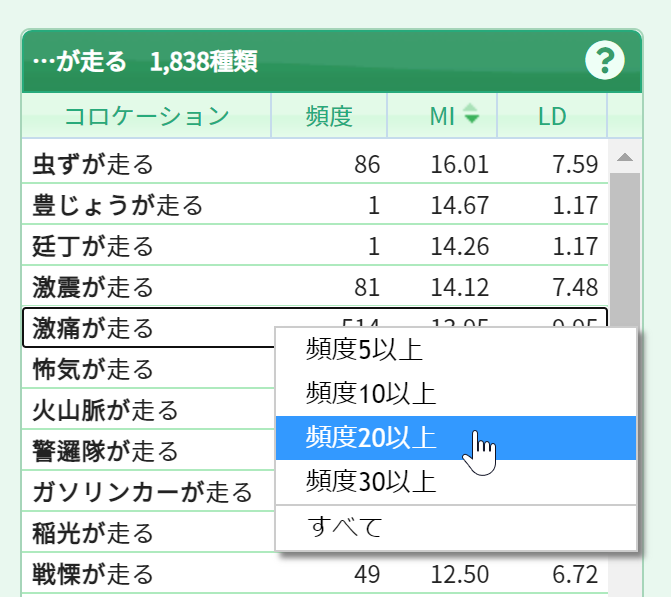
次に、特徴的なコロケーションを表示してみます。NLTでは、頻度順だけでなくMIスコアの順でも並べ替えることができます。MIスコアは統計指標の一つで、特徴的なコロケーションほど数値が高くなる傾向があります。ただし、低頻度のコロケーションの数値が過剰に高くなるため、低頻度のものを排除する必要があります。コロケーションパネルのヘッダーの[MI]をクリックしてから、パネル上で右クリックして[頻度20以上]を選びます。
すると、「虫ずが走る」、「戦慄が走る」などの「名詞+が走る」の特徴的な表現が上位に現れます。
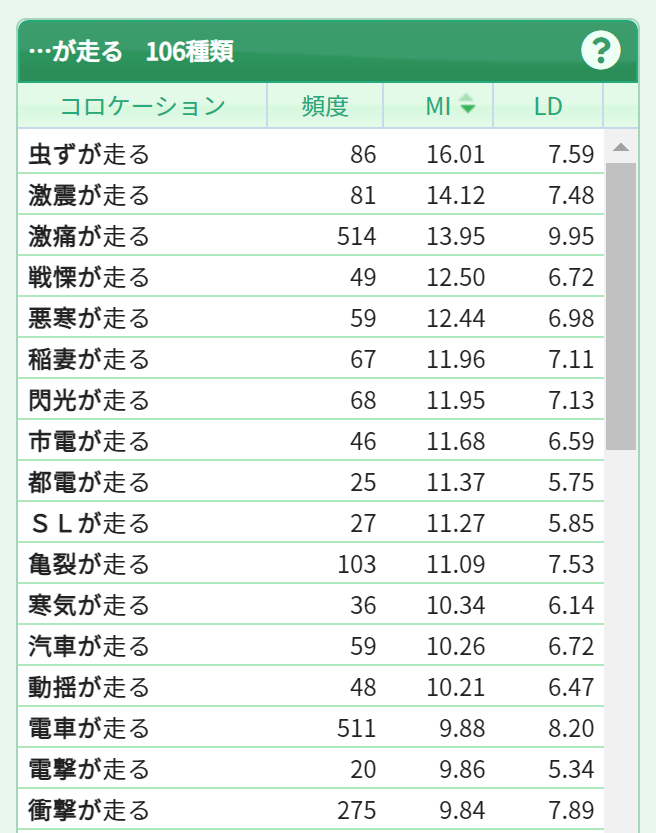
それぞれのコロケーションをクリックすると、右のパネルにその用例が表示されます。ここでは、7番目の「閃光が走る」をクリックしてみます。コーパスで使われている実際の用例を一つずつ確認することができます。
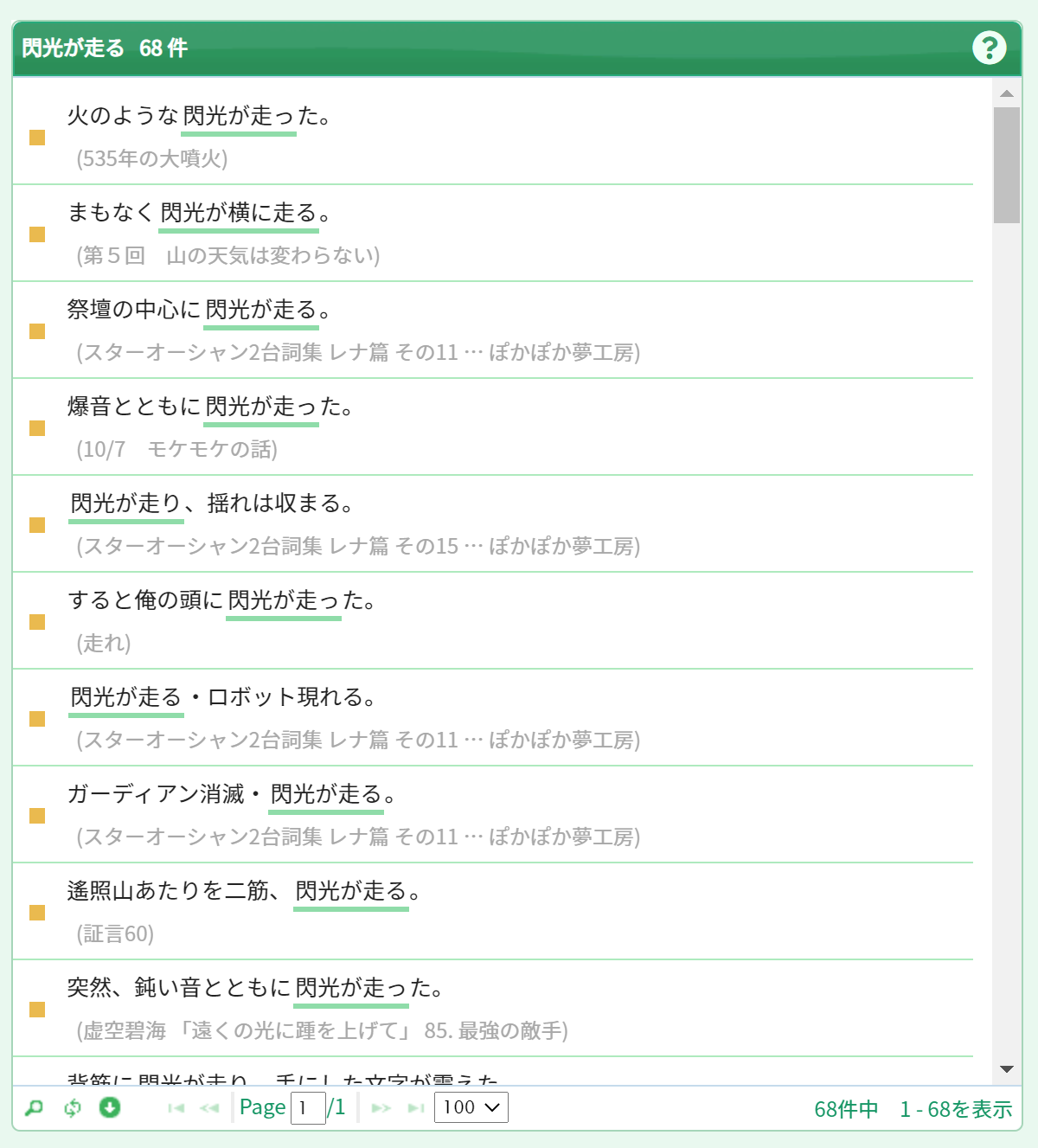
用例はセンテンス単位で表示されます。さらに前後の文脈を確認するときは、それぞれの用例の出典の部分をクリックすると、前後のセンテンスを表示するダイアログが開きます。

このように、NLTでは、検索ウィンドウでまず見出し語を選んで、見出し語ウィンドウ上で、文法パターン、コロケーション、用例を行き来しながら、その見出し語の振る舞いの全体像をつかむことができます。クリックだけで簡単に操作できますので、思考を途切らせることなくさまざまな表現を思いのままに調べることができます。
詳しい使い方については、ユーザーガイド(PDFファイル、約2.8MB)をご覧ください。
■2語比較機能
バージョン1.30では、新たに2語比較機能が加わりました。比較できるのは、同一の品詞の内容語(名詞、動詞、イ形容詞、ナ形容詞、連体詞、副詞)の組み合わせです。これ以外に、イ形容詞とナ形容詞、イ形容詞と連体詞、ナ形容詞と連体詞の比較も可能です。
ここでは、「冷える」と「冷める」という2つの動詞について調べてみます。見出し語検索のウィンドウの右上にある[2語比較検索]のボタンをクリックします。

次に、[動詞」タブをクリックします。
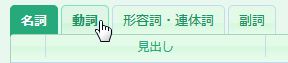
画面上の入力ボックスに「ひえる」と「さめる」(カタカナ、ローマ字も可)をスペースで区切って入力して、[絞り込み]ボタンをクリックします。下のリストに「ひえる」と「さめる」という読みをもつ見出し語が現れます。
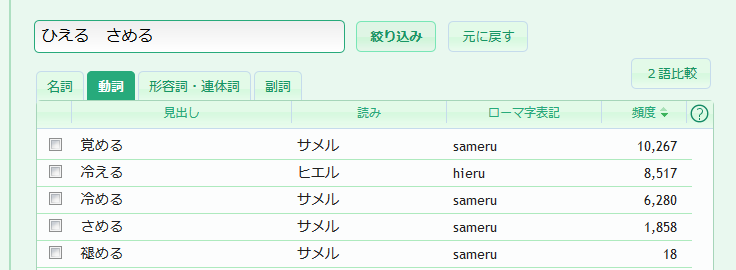
比較したい2語(ここでは、「冷える」と「冷める」)にチェックマークを入れて、リストの右上にある[2語比較]ボタンをクリックします。
「冷える」と「冷める」の2語比較のウィンドウが開きます。
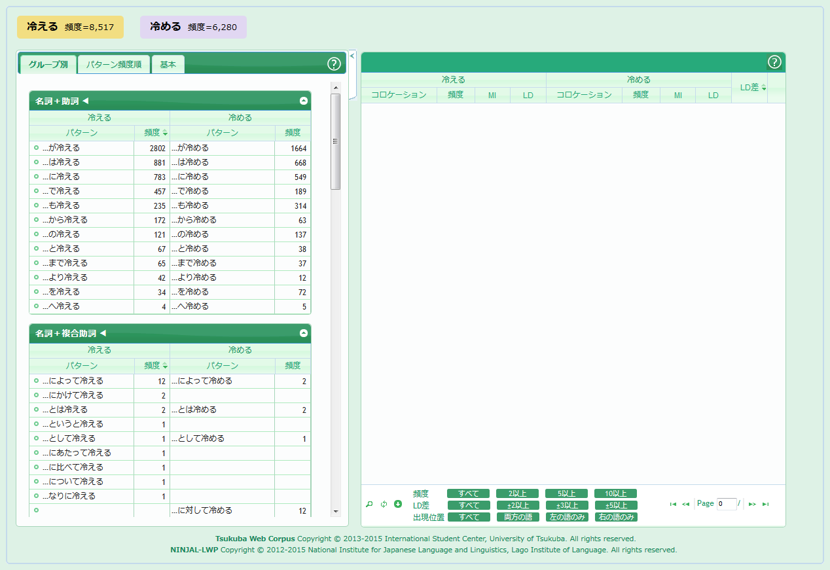
ここでは、ガ格名詞を比較してみます。左側の文法パターンパネルの一番上にある「…が冷える」または「…が冷める」のパターンをクリックします。
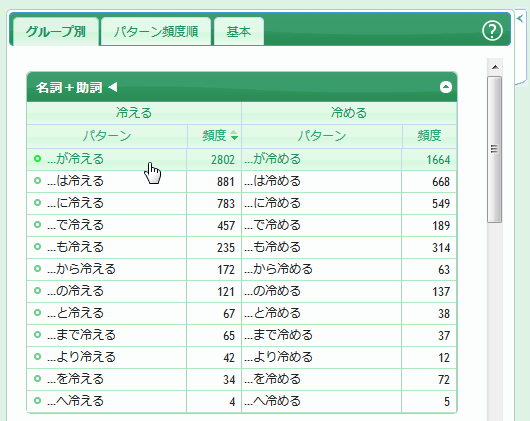
すると、中央のコロケーションパネルに「…が冷える」と「…が冷める」が表示されます。
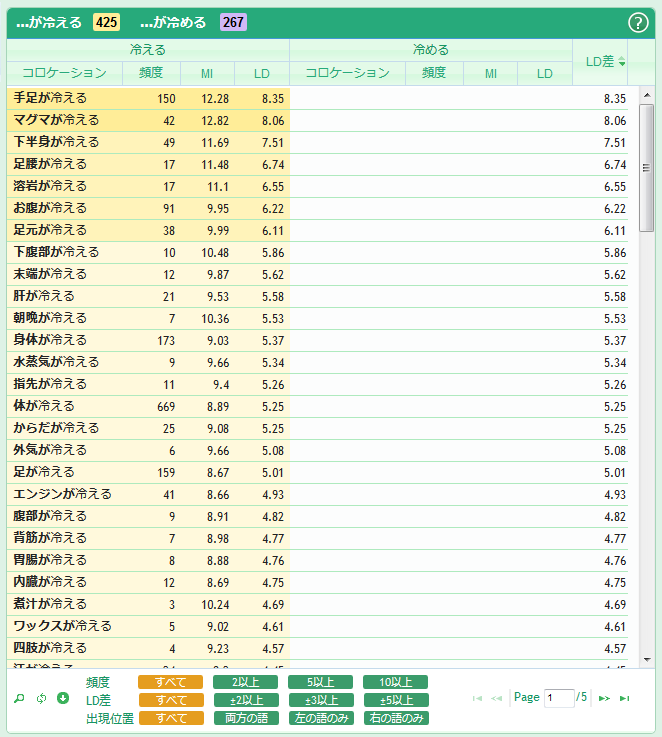
最初の状態では、コロケーションはLD差の降順に並んでいます。LD差というのは、左側のコロケーション(この場合は、「…が冷える」)のLD(ログダイス値)から、右側のコロケーション(この場合は、「…が冷める」)のLDを引いたものです。LD差が大きくなればなるほど、「…が冷える」の特徴的なコロケーションと言えます。逆に、LD差が小さくなればなるほど、「…が冷める」の特徴的なコロケーションになります。視覚的に理解しやすいように、LD差が大きくなるほど濃い黄色で、LD差が小さくなるほど濃い紫でハイライトされます。上の画面では、「…が冷える」の特徴的なコロケーションが表示されていますが、「…が冷める」の特徴的なコロケーションを見るときは、[LD差]のヘッダーをクリックして、LD差の昇順に並べ替えます。

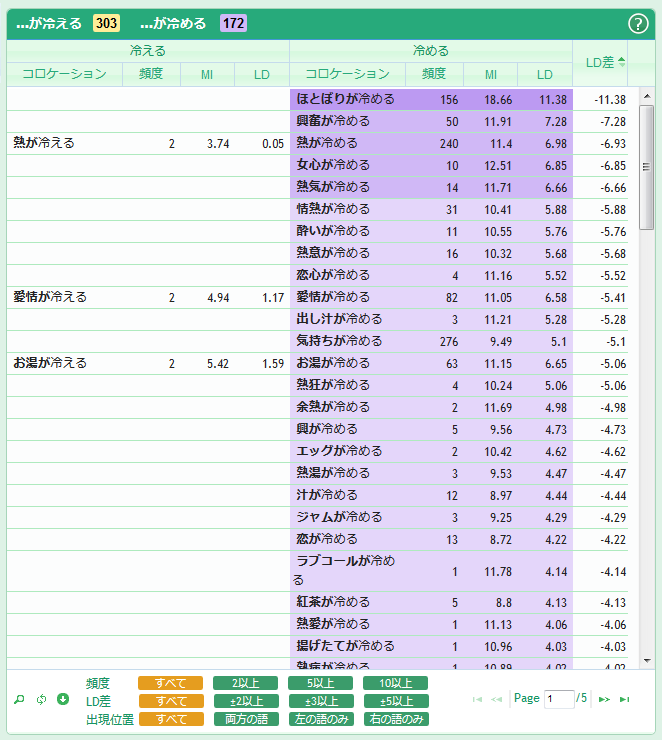
両方のコロケーションを詳細に分析するために、コロケーションパネルのフッターに3種類のボタンセットが用意されています。このボタンを組み合わせることで、頻度、LD差、出現位置(2語のうちどちらの語と共起しているか、両方か、どちらか一方か)を自由に調整して、分析を進めることができます。

これ以外に、両方の語に共通するコロケーションの違いを用例レベルで調べることなどもできます。詳しい使い方については、操作説明書(PDFファイル、約2.8MB)の10節をご覧ください。
■筑波ウェブコーパスの構築
TWC ver.1.40では、日本語のウェブサイトから収集した11億3800万語のデータを使用しています。
ウェブ上からのテキストの収集では、検索エンジンのAPIを利用して、ウェブページのURLを収集した後、そのURLのデータを収集する一般的な手法に従っています。以下が具体的なコーパス構築の手順です。
| ● | シードおよびタプルの生成 | |||
| 検索エンジンのクエリパラメータに与えるタプルを構成するシードには、NLBの開発過程で作成したBCCWJ(2009年の領域公開データの一部、約6千2百万語)の頻度リストを利用しました。品詞ごとに分かれた頻度リストのうち、内容語である名詞、動詞、形容詞、副詞のリストをマージして、上位500語をシードとして選びました。ただし、名詞のうち、数詞、固有名詞は排除し、また、動詞、形容詞については活用形も含めました。この500語のシードから無作為に3語を選び出し、計50万組のタプルを作成しました。以下にタプルの例を示します。 | ||||
| ||||
| ● | 検索エンジンAPIによるURLの収集 | |||
| URLの収集には、Yahoo!ウェブ検索APIを利用しました。1タプル当たりで収集するURL数は10ページとし、2012年1月初旬から下旬にかけて計500万URLを収集しました。重複したURLを削除したURL総数は約3割減の約350万件になりました。 | ||||
| ● | HTMLページの収集 | |||
| URLデータを5万件ごとに分割した上で、3台の端末を利用して2週間をかけてHTMLページを収集しました。 | ||||
| ● | テキストの抽出 | |||
| 次に収集したHTMLファイルからテキストを抽出する作業を行いました。具体的には、HTMLタグの削除、文字コードの統一(utf8)、日本語以外の言語で書かれたテキストの削除などの作業を行いました。 | ||||
| ● | 不適正なページの排除 | |||
| ウェブ上のテキストの収集の目的は日本語の用例を採取することにあるので、単に項目やリンクを列挙しただけのページ、広告と思われる内容の多いページ、センテンス境界の判定が難しいページは、あらかじめコーパスデータの対象から外しました。 | ||||
| ● | センテンスの抽出 | |||
| レキシカルプロファイリングツールNINJAL-LWPでは、センテンス単位にした用例の中にどのようなコロケーションが含まれるかを文法パターン別に抽出します。そのため、コーパスデータはあらかじめセンテンス単位に分割しておく必要があります。一つ前の作業でセンテンス境界の判定が難しいページを排除したのもこの理由によります。 | ||||
| ● | 用例データの抽出 | |||
| センテンス単位のデータのなかには、見出しに相当するものや、メニュー項目に相当するものが含まれています。センテンス中にどの程度名詞が含まれるか、センテンス中に動詞は現れるか、「クリック」や「ログイン」などのウェブページで多用される表現が用いられているかなどの複数の観点から、用例としての適正度を数値化し、用例としてふさわしいデータを抽出しました。また、同一ページで同じセンテンスが現れた場合も、最初の1件のみを用例として採取し、不要な重複を避ける工夫をしました。 | ||||
| ● | 重複する用例データの削除 | |||
| 一つ前の作業で、同一ページでは同じ用例が複数回採取されないようにしましたが、6億語弱のパイロット版NLTを開発して実際に運用してみたところ、同一サイトで同一の用例が頻出することが確認されました。そのため、URLの情報をもとに同一サイト での同じ用例は一度だけ採取するように改良し、最終的に語数にして11億3781万語、用例数にして4672万7千例の筑波ウェブコーパスが完成しました。 |
■アノテーション
NLTでは、コロケーションや文法的振る舞いの情報を抽出するために、BCCWJのデータにアノテーションを付与した上で解析しています。アノテーションに使用している解析器・辞書は以下の通りです。
■ご利用にあたって
| 1. | 【動作環境】ブラウザはFirefox、Chrome、Safari、IE(バージョン8以上)に対応しています。処理速度の観点から、Firefox、Chrome、Safariのご利用をお勧めします。 | |
| 2. | 【クッキーの設定】使用にあたってはブラウザのクッキーをオンにしてください。オフにした状態ではデータが表示されません。クッキーをオンにする方法については、各ブラウザのマニュアル等でご確認ください。 | |
| 3. | 【表示結果】NLTでは、機械的に処理した結果をそのまま表示しています。形態素・係り受け解析や抽出処理の精度の限界により不適切なデータが混入しています。あらかじめご了承ください。 | |
| 4. | 【論文・記事を公表する場合】NLTを研究・教育に利用して論文や記事を執筆される場合は、以下のように、必ずNLTを利用した旨を明記し、筑波大学グローバルコミュニケーション教育センター日本語・日本事情遠隔教育拠点(jp-kyoten(アットマーク)un.tsukuba.ac.jp)までご連絡ください。
| |
| 5. | 【用例の削除依頼】このコーパスは、教育・研究目的で、ウェブ上からデータを収集したものです。すべての用例は出所先であるページのタイトルとURLを明記した上で表示しています。自らが著作権を有するウェブページから抽出された用例の削除を希望される場合は、お問い合わせのメールアドレスまでご連絡ください。申請者ご本人のページであることを確認した上で削除させていただきます。 |
■見出し語頻度リスト
見出し語の頻度リストです。Excelファイル形式(xlsx)になっています。ご利用にあたっては、研究・教育目的に限定します。詳しくは、ファイル内の「ご利用にあたって」をご覧ください。
■更新履歴
| 2013/4/15 | NLT ver.1.10 公開 |
| 2015/3/27 | NLT ver.1.30 公開(2語比較機能追加) |
| 2019/4/26 | 見出し語の頻度リストを公開 |
| 2020/11/16 | ドメインをtsukubawebcorpus.jpに変更、常時SSL対応 |
| 2021/3/16 | NLT ver.1.40 公開(多国語版) |
| 2023/9/28 | 動詞見出しの「形容詞+動詞」パターン修正 |
■お問い合わせ
NLTに関するお問い合わせは以下までお願いいたします。
jp-kyoten(アットマーク)un.tsukuba.ac.jp